728x90
챕터 8 이상탐지
이상탐지
- 데이터에서 '정상 패턴'과 크게 다른 행위를 보이는 특이한 패턴(이상, anomaly)을 찾는 기법
- 예) 정상 거래 내역과 비교했을 때 매우 높은 금액을 단숨에 인출하는 거래, 센서 신호가 갑자기 급등 또는 급락하는 경우 등
이상탐지의 필요성
- 금융 사기
카드 사기, 계좌 해킹 등으로 인한 금전적 손실을 미리 막기 위해 - 제조업
생산 라인이나 기계 설비에서 발생하느 고장을 사전에 예측하여 유지보수 비용 절감, 다운타임 최소화 - 보안
네트워크 침입 시도나 데이터 탈취 등을 빠르게 감지
이상치 탐지(Outlier Detection)와의 차이
- 이상치 탐지는 단순히 통계적으로 극단값을 찾는 데 초점을 둠. 예를 들어 평균에서 크게 벗어난 데이터 포인트를 찾는 방식
- 이상 탐지는 단순 극단값 뿐 아니라, 맥락이나 시계열 상의 패턴을 함께 고려하여 '비정상'인지를 판단하는 것을 의미하는 경우가 많음
예) 시간적 흐름이나 주변 맥락, 다른 변수들과의 상관관계까지 고려하는 경우
주요 이상 탐지 알고리즘
One-Class SVM

알고리즘 원리
- SVM(Support Vector Machine)은 원래 이진 분류를 위해 고안된 알고리즘이지만, One-Class SVM은 '단 하나의 클래스(정상 클래스)'만을 학습해 해당 클래스 영역을 정의
- 정상 데이터가 분포하는 공간 주위에 경계를 형성("decision boundary")하고, 경계 밖에 있는 데이터는 '비정상'으로 분류
특징
- 고차원 공간에서도 비교적 잘 동작할 수 있음(커널 함수의 사용)
- 데이터 스케일링과 커널 파라미터 선택이 중요
Isolation Forest

알고리즘 원리
- Isolation Forest는 랜덤포레스트와 유사한 아이디어에 기반
- "이상치(이상 데이터)는 전체 데이터 중 상대적으로 적고, 특정 속성값에서 극단적인 위치를 차지하는 경우가 많다"는 가정 하에, 무작위로 특성과 분할값을 골라 데이터를 계속 나누어가는 과정에서 '쉽게 분리(또는 격리)되는' 데이터는 이상일 가능성이 높다고 봄
특징
- 랜덤 포레스트 방식으로 여러 개의 무작위 트리를 구성하고, 각 트리에서 한 데이터가 분리되는 "깊이"를 측정하여 이상 점수를 부여
- 대규모 데이터셋에서도 빠르게 동작하는 편이며, 구현이 간단하고 직관적
이상탐지 코드
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
# 1. 데이터 로드: Iris 데이터셋
from sklearn.datasets import load_iris
data = load_iris()
X = data.data
y = data.target # 여기서는 실제 라벨을 이용하지 않음
# 간단히 2개 특성만 사용 (예: 꽃받침 길이, 꽃받침 너비) --> 시각화 편의를 위해
X_2d = X[:, :2] # shape: (150, 2)
# 2. One-Class SVM
from sklearn.svm import OneClassSVM
oc_svm = OneClassSVM(nu=0.05) # 예시 파라미터
oc_svm.fit(X_2d)
# 예측: 1(정상), -1(이상치)
y_pred_oc = oc_svm.predict(X_2d)
# 3. Isolation Forest
from sklearn.ensemble import IsolationForest
iso_forest = IsolationForest(contamination=0.05, random_state=42)
iso_forest.fit(X_2d)
# 예측: 1(정상), -1(이상치)
y_pred_if = iso_forest.predict(X_2d)
# 4. 이상치로 예측된 샘플 인덱스 추출
outliers_oc = np.where(y_pred_oc == -1)[0] # One-Class SVM이 예측한 이상치
outliers_if = np.where(y_pred_if == -1)[0] # Isolation Forest가 예측한 이상치
print("=== One-Class SVM ===")
print("이상치로 탐지된 샘플 개수:", len(outliers_oc))
print("이상치 인덱스:", outliers_oc)
print("\n=== Isolation Forest ===")
print("이상치로 탐지된 샘플 개수:", len(outliers_if))
print("이상치 인덱스:", outliers_if)
# 5. 시각화
# 2차원 특성 공간에서 이상치로 판별된 점들을 빨간색으로 표시
fig, axes = plt.subplots(1, 2, figsize=(12, 5))
axes[0].scatter(X_2d[:, 0], X_2d[:, 1], label='Normal')
axes[0].scatter(X_2d[outliers_oc, 0], X_2d[outliers_oc, 1],
color='red', edgecolors='k', label='Outliers')
axes[0].set_title("One-Class SVM")
axes[0].set_xlabel("Sepal Length")
axes[0].set_ylabel("Sepal Width")
axes[0].legend()
axes[1].scatter(X_2d[:, 0], X_2d[:, 1], label='Normal')
axes[1].scatter(X_2d[outliers_if, 0], X_2d[outliers_if, 1],
color='red', edgecolors='k', label='Outliers')
axes[1].set_title("Isolation Forest")
axes[1].set_xlabel("Sepal Length")
axes[1].set_ylabel("Sepal Width")
axes[1].legend()
plt.tight_layout()
plt.show()산업별 사례
금융 분야
카드 사기 거래(Fraud Detection)
- 수많은 정상 거래 데이터를 토대로 이상 탐지 모델을 학습
- 갑작스러운 해외 거래나, 큰 금액의 잦은 이체 등의 패턴이 감지되면 사기 가능성이 높은 것으로 표시
돈세탁 의심 거래(Money Laundering)
- 고객의 거래 패턴(빈도, 금액, 거래처 등)을 종합적으로 분석하여, 비정상적으로 복잡한 자금 흐름을 포착
제조업 분야
설비 고장 예측
- 온도, 압력, 진동 센서 데이터를 장기간 축적해 정상 범위를 학습
- 특정 시점부터 갑작스럽게 진동 값이 크게 변한다면, 실제 고장 가능성이 있는 설비로 판단해 미리 점검
품질 이상 탐지
- 생산 공정 중 수집되는 다양한 품질 지표(크기, 무게, 색상 등)를 통해 갑작스러운 편차가 발생하는 제품을 빠르게 걸러내어 불량률을 줄임
챕터 9 딥러닝
딥러닝 기본 개념
인공신경망(ANN)의 역사와 발전
- 1940~50년대 초창기 뉴런을 단순 모델로 삼아 연구 시작
- 퍼셉트론의 단층 구조 -> 다층퍼셉트론 -> 딥러닝
- 왜 '딥'인가?
입력 계층(Input Layer)과 출력 계층(Output Layer) 사이에 여러 개의 은닉층(Hidden Layer)을 두어 복잡한 패턴까지 학습 가능 - 데이터와 컴퓨팅 파워, 알고리즘 발전으로 딥러닝이 급성장
딥러닝의 핵심 아이디어
- 계층적 특징 학습
예) 사람 얼굴 인식을 예로 들면, 초기 은닉층에서는 '선', '모서리', '곡선' 등을 잡아내고, 더 깊은 층에서는 '코, 눈, 입' 등 구체적 특징을 학습하며, 마지막에는 얼굴 전체를 인식 - 비선형 변환을 반복 적용
많은 은닉층이 비선형 활성화 함수를 통해 데이터를 변환하면서 복잡한 패턴을 학습
- 오차 역전파(Backpropagation)
예측과 실제 값의 차이를 신경망 거꾸로 전달하며 가중치를 업데이트
딥러닝 적용 절차(머신러닝 방법과 동일)
- 데이터 수집
- 데이터 전처리(결측치 처리, 정규화 등)
- 모델 설계
- 모델 학습(훈련)
- 검증(Validation) 및 성능 평가
- 최종 모델 활용
주요 딥러닝 아키텍처
CNN(Convolutional Neural Network)

개념
- 주로 이미지, 영상에 특화된 구조
- 합성곱(Convolution) 연산을 통해 픽셀 영역의 지역적 특성을 추출
작동 원리
- 합성곱 레이어:
필터(또는 커널)을 이용해 이미지(특징 맵)을 스캔하며 특징을 추출 - 풀링(Pooling) 레이어:
특징 맵의 크기를 줄이고 주요 특징만 요약 - 완전연결(FC, Fully Connected) 레이어:
추출된 특징 기반으로 분류나 회귀 수행
활용 예시
- 자율주행 차량에서 도로 표지판 인식, 차선 탐지, 물체 인식(보행자, 차량 등)
- 의료 영상 분석(CT, MRI 등)에서 질병 부위 정확 탐지
- 이미지를 볼 때 큰 그림을 보는 것이 아니라 일정 크기의 창으로 이미지를 훑으며(스캔) 특징을 찾는 방식
RNN(Recurrent Neural Network)

개념
- 순차적(시퀀스) 데이터 처리에 특화된 신경망 구조
- 문장(텍스트), 음성 신호, 주가 등 시간 순서가 있는 데이터를 다룸
작동 원리
- 이전 단계(시점)의 은닉 상태(정보)를 다음 단계로 넘겨주며 연쇄적으로 학습
- 순환 구조로 인해 과거의 정보를 기반으로 현재 출력에 영향을 줌
문제점과 개선
- 장기 메모리 문제가 발생(기울기 소실, 폭주 문제) -> LSTM(Long Short-Term Memory), GRU(Gated Recurrent Unit)으로 개선
활용 예시
- 음성 인식, 기계 번역, 감정 분석, 시계열 예측(주가, 날씨 등)
- 우리 뇌가 문장을 읽을 때 앞 단어(이전 맥락)를 기억하며 현재 단어를 이해하듯, RNN은 이전 정보를 순환하며 학습
Transformers
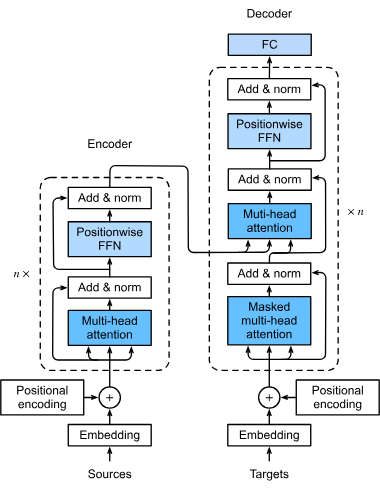

개념
- 2017년 구글 논문("Attention is All You Need")에서 제시된 모델
- 어텐션(Attention) 메커니즘을 활용하여, 입력 전체에서 중요한 부분에 집중
- RNN 없이도 순차 데이터(문장 등) 처리가 가능 -> 병렬 연산이 가능해 학습 속도 대폭 향상
작동 원리
- 인코더(Encoder)와 디코더(Decoder) 구조로 분리
- 어텐션을 통해 단어 간 연관성(의미, 문맥)을 효율적으로 학습
활용 예시
- BERT, GPT 시리즈 등 대형 언어 모델
- 최신 NLP 작업 전반(번역, 요약, 질의응답, 텍스트 생성 등)에 활용
중요성
- 현재 많은 대형 모델들이 Transformers 기반
- 자연어 처리뿐 아니라 영상, 음성 등 멀티모달에도 응용 가능
- 사람에게 한 문단 전체를 빠르게 보여주고, 어떤 단어가 서로 얼마나 관련있는지 파악해 의미 연결고리를 만드는 과정
딥러닝의 주요 활용 사례
이미지 처리
예시1 : 의료 영상 분석
- CT, MRI 등을 분석해 종양이나 이상 부위를 빠르게 검출 -> 진단 보조 역할
- 인공지능 진단 보조 시스템으로 의료진 부담 완화 및 정확도 향상
예시2 : 자율주행 객체 탐지
- 도로 상황에서 차량, 보행자, 신호등 등의 위치와 종류 인식
- CNN 기반의 물체 인식(Object Detection) 알고리즘(YOLO, Faster R-CNN 등) 활용
자연어 처리(NLP)
예시1 : 감정 분석
- SNS나 상품 리뷰 문장에서 "긍정/부정", "화남/기쁨" 등을 자동 분류
- 고객 만족도 분석, 마케팅 전략 수립에 활용
예시2 : 음성 인식
- 스마트 스피커(Siri, Alexa 등), 콜센터 자동 응답 시스템
- RNN, Transformer 기반 음성 -> 텍스트 변환
예시3 : 기계 번역, 요약
- 구글 번역, 파파고, 딥엘(DeepL) 등 고품질 번역 서비스
- 긴 텍스트를 핵심만 추려 요약하는 자동 요약 기술
생성형 AI (Generative AI)
텍스트 생성
- ChatGPT, GPT 시리즈 등은 거대 언어 모델(LLM, Large Language Model)로 자연스러운 문장 생성
- 블로그 글 작성, 보고서 초안 작성, 스토리텔링에 활용
이미지 생성
- DALL-E, Midjourney, Stable Diffusion 등 이미지 생성 모델
- 예술, 디자인 분야에서 컨셉 아트나 시각 자료 생성
음악/영상 생성
- 새로운 멜로디, 편곡, 스타일의 음악을 생성하거나 영상 편집 보조 등에 활용
- 유튜브 콘텐츠 제작 보조
강화학습(Reinforcement Learning)

- 에이전트가 환경과 상호작용하며, 행동에 따라 보상을 받아 학습
- 보상을 최대화하는 방향으로 정책(Policy)을 학습해 최적의 행동을 찾음
예시
- 알파고(AlphaGo) : 바둑에서 승리 보상을 최대화하기 위해 강화학습
- 로봇 제어 : 로봇이 넘어지지 않고 걷는 법, 장애물 피하기 등
응용 분야
- 게임(AI 플레이어), 추천 시스템, 자율주행(주행 정책 학습), 산업 자동화 등
감정분석 코드
from transformers import pipeline
# 1) 텍스트 분류 파이프라인 생성 (감정 분석용 사전학습 모델)
classifier = pipeline("sentiment-analysis")
# 2) 예시 문장 분석
texts = [
"I love this product! It's absolutely wonderful.",
"I'm really disappointed. It didn't work as expected."
]
results = classifier(texts)
print(results)질의응답 코드
from transformers import pipeline
# 1. "question-answering" 파이프라인을 생성
qa_pipe = pipeline(
"question-answering",
model="distilbert-base-uncased-distilled-squad"
)
# 2. 예시 지문(context)과 질문(question)
context = """
Hugging Face is a company that provides an open-source community and a platform of
transformer models. Their Transformers library allows easy usage of state-of-the-art
natural language processing models. They focus on facilitating accessibility and
collaboration in the AI field.
"""
question = "What does Hugging Face provide?"
# 3. 질의응답 수행
result = qa_pipe(question=question, context=context)
print(result)
# 예시 출력:
# {'score': 0.930..., 'start': 59, 'end': 122, 'answer': 'an open-source community and a platform of transformer models'}문장생성 코드
from transformers import pipeline
# 1) 텍스트 생성 파이프라인 (GPT-2 등 사전학습 모델 기반)
generator = pipeline("text-generation", model="gpt2")
# 2) 예시 프롬프트 (문장 시작)
prompt = "Once upon a time, in a land far away"
# 3) 문장 자동 완성
result = generator(prompt, max_length=50, num_return_sequences=1)
print(result)